
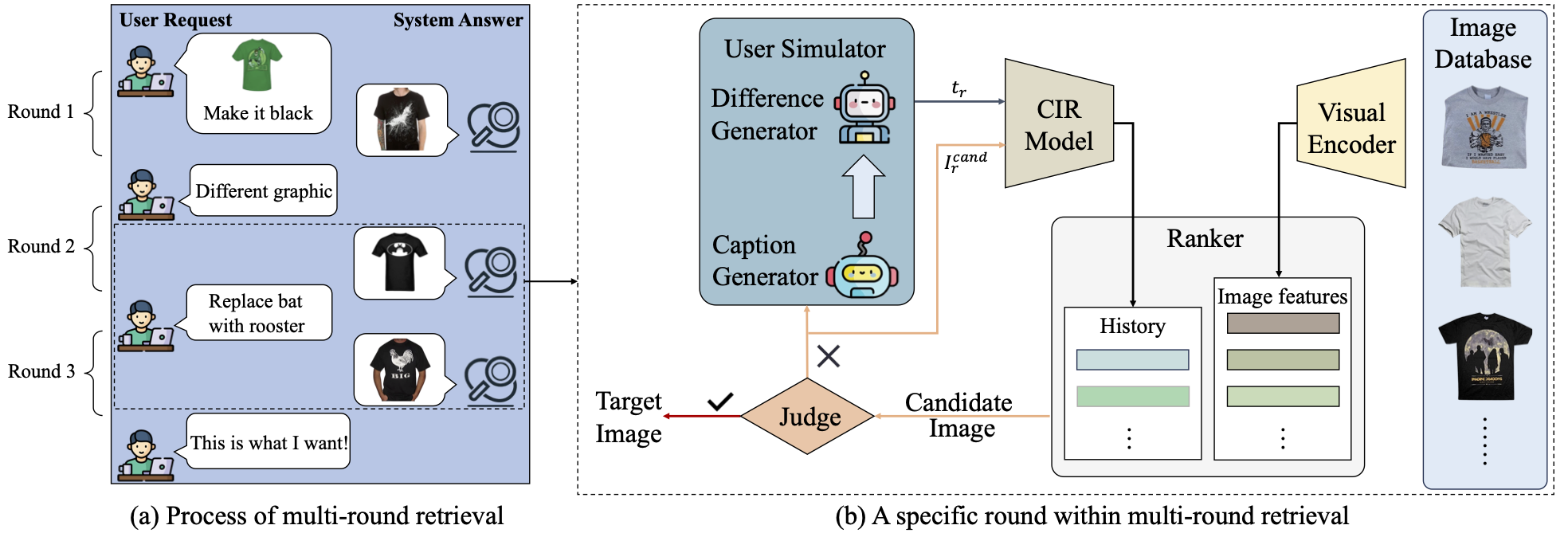
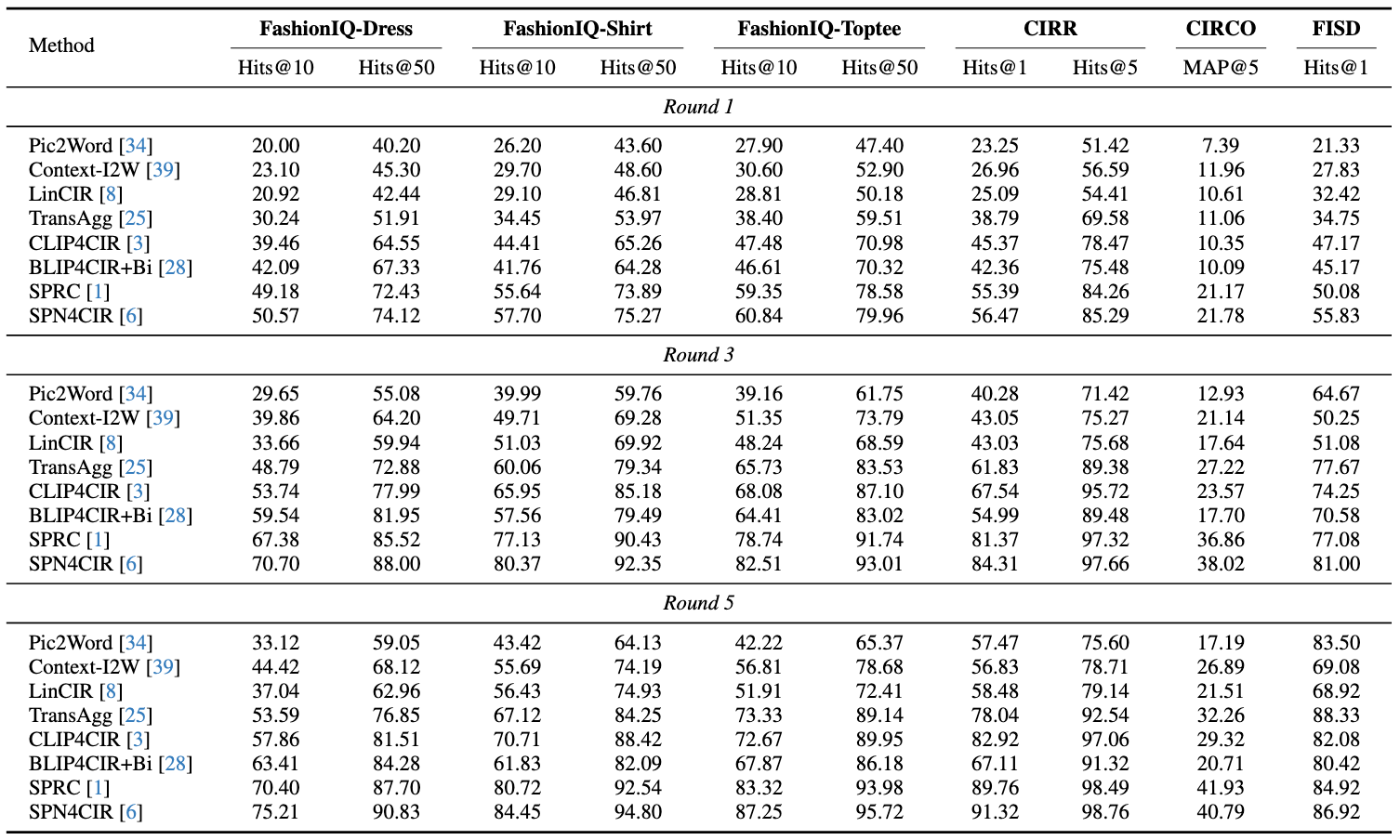
Composed Image Retrieval (CIR) aims to retrieve a target image based on a query composed of a reference image, and a relative caption that specifies the desired modification. Despite the rapid development of CIR models, their performance is not well characterized by existing benchmarks, which inherently contain indeterminate queries degrading the evaluation (i.e., multiple candidate images, rather than solely the target image, meet the query criteria), and have not considered their effectiveness in the context of the multi-round system. Motivated by this, we consider improving the evaluation procedure from two aspects: 1) we introduce FISD, a Fully-Informed Semantically-Diverse benchmark, which employs generative models to precisely control the variables of reference-target image pairs, enabling a more accurate evaluation of CIR methods across six dimensions, without query ambiguity; 2) we propose an automatic multi-round agentic evaluation framework to probe the potential of the existing models in the interactive scenarios. By observing how models adapt and refine their choices over successive rounds of queries, this framework provides a more realistic appraisal of their efficacy in practical applications. Extensive experiments and comparisons prove the value of our novel evaluation on typical CIR methods.


@article{liu2026versavit,
title={VersaViT: Enhancing MLLM Vision Backbones via Task-Guided Optimization},
author={Yikun Liu and Yuan Liu and Shangzhe Di and Haicheng Wang and Zhongyin Zhao and Le Tian and Xiao Zhou and Jie Zhou and Jiangchao Yao and Yanfeng Wang and Weidi Xie},
journal={arXiv preprint arXiv:2602.09934},
year={2026}
}