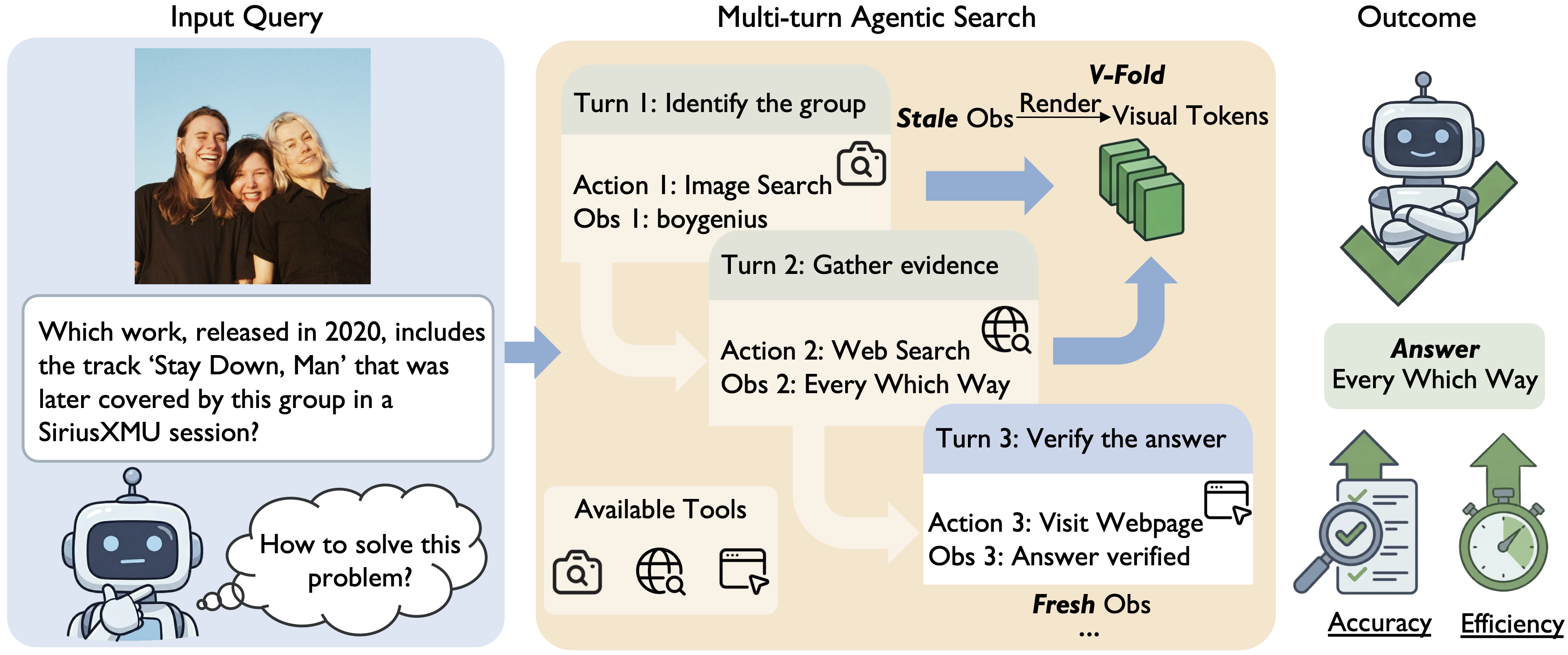
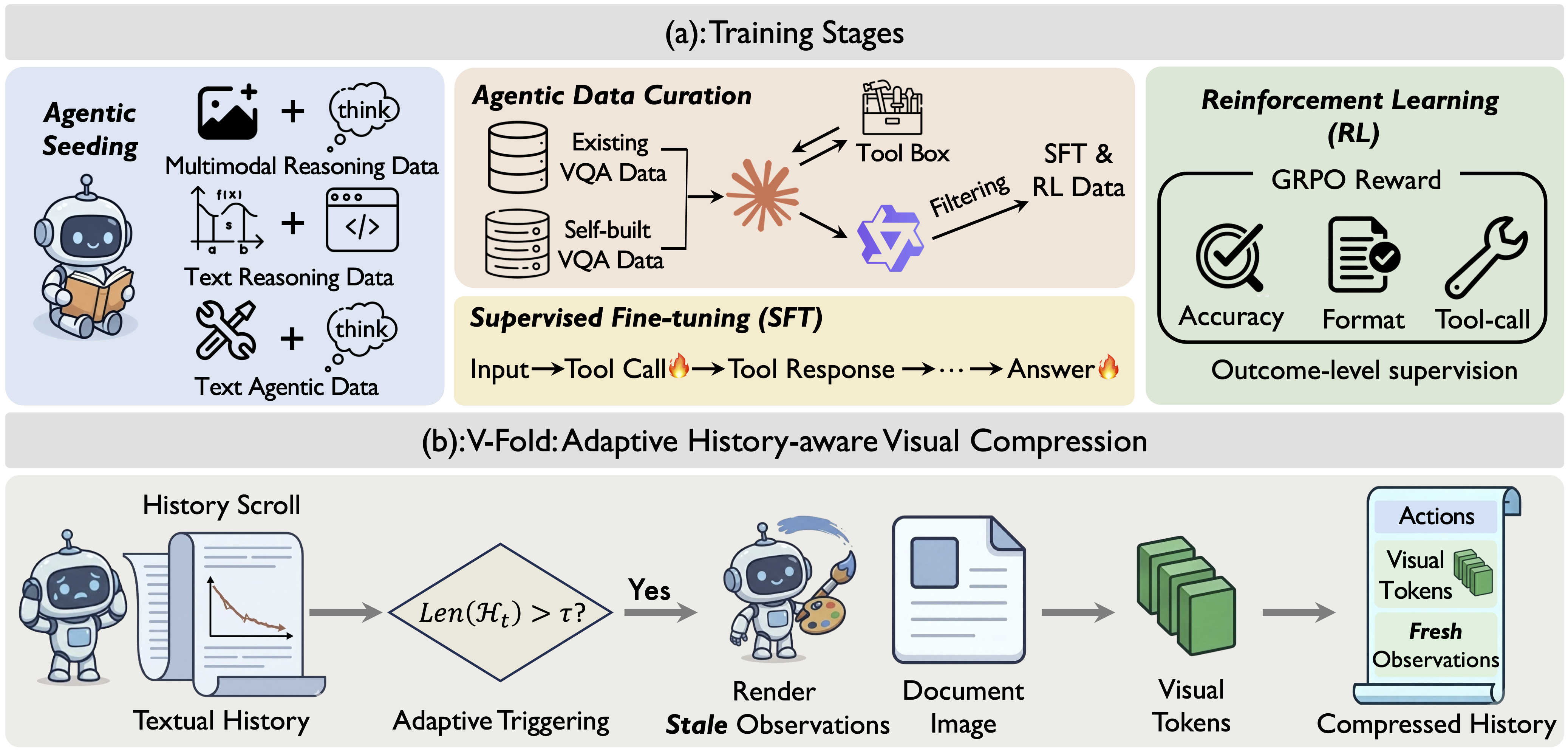
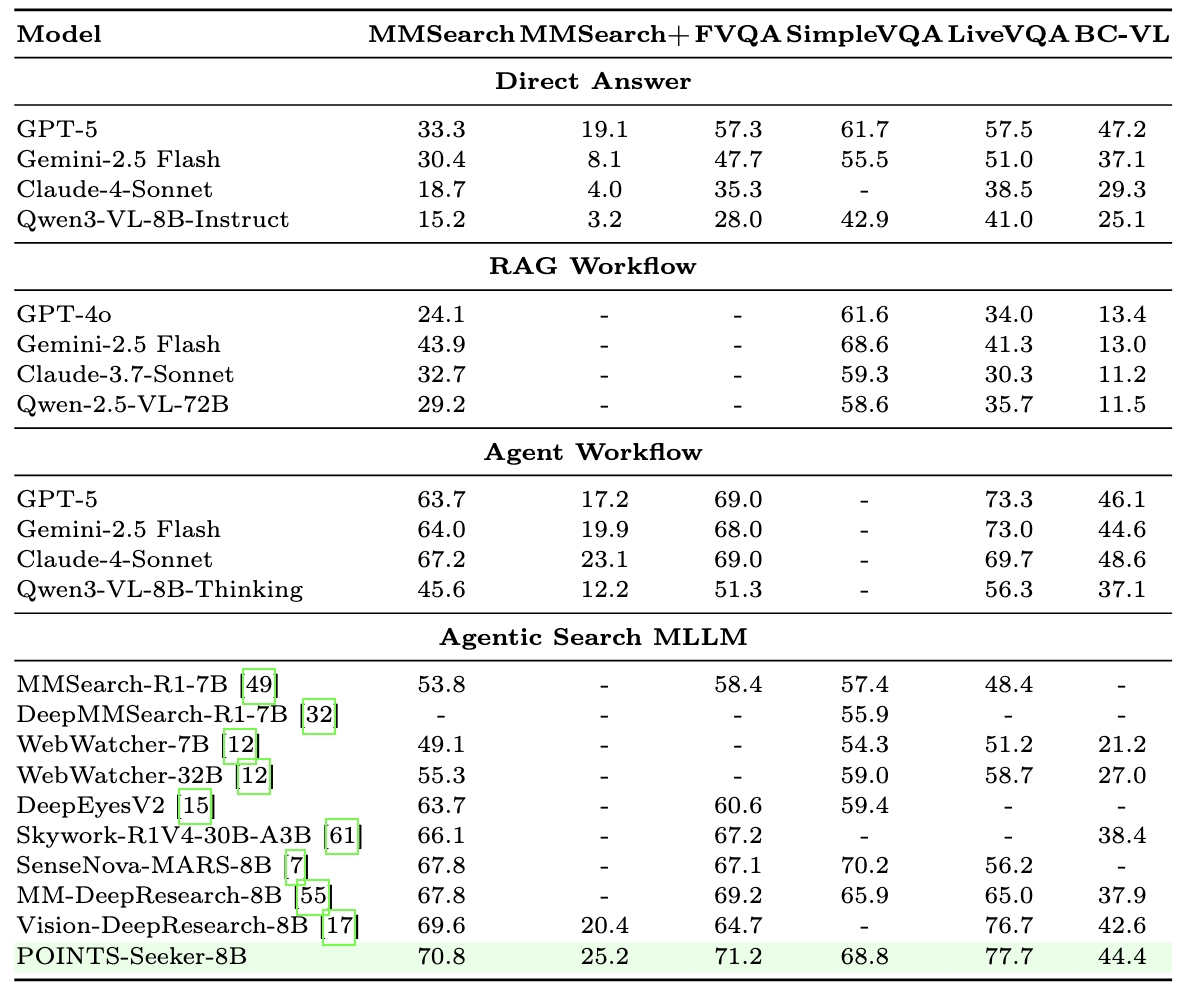
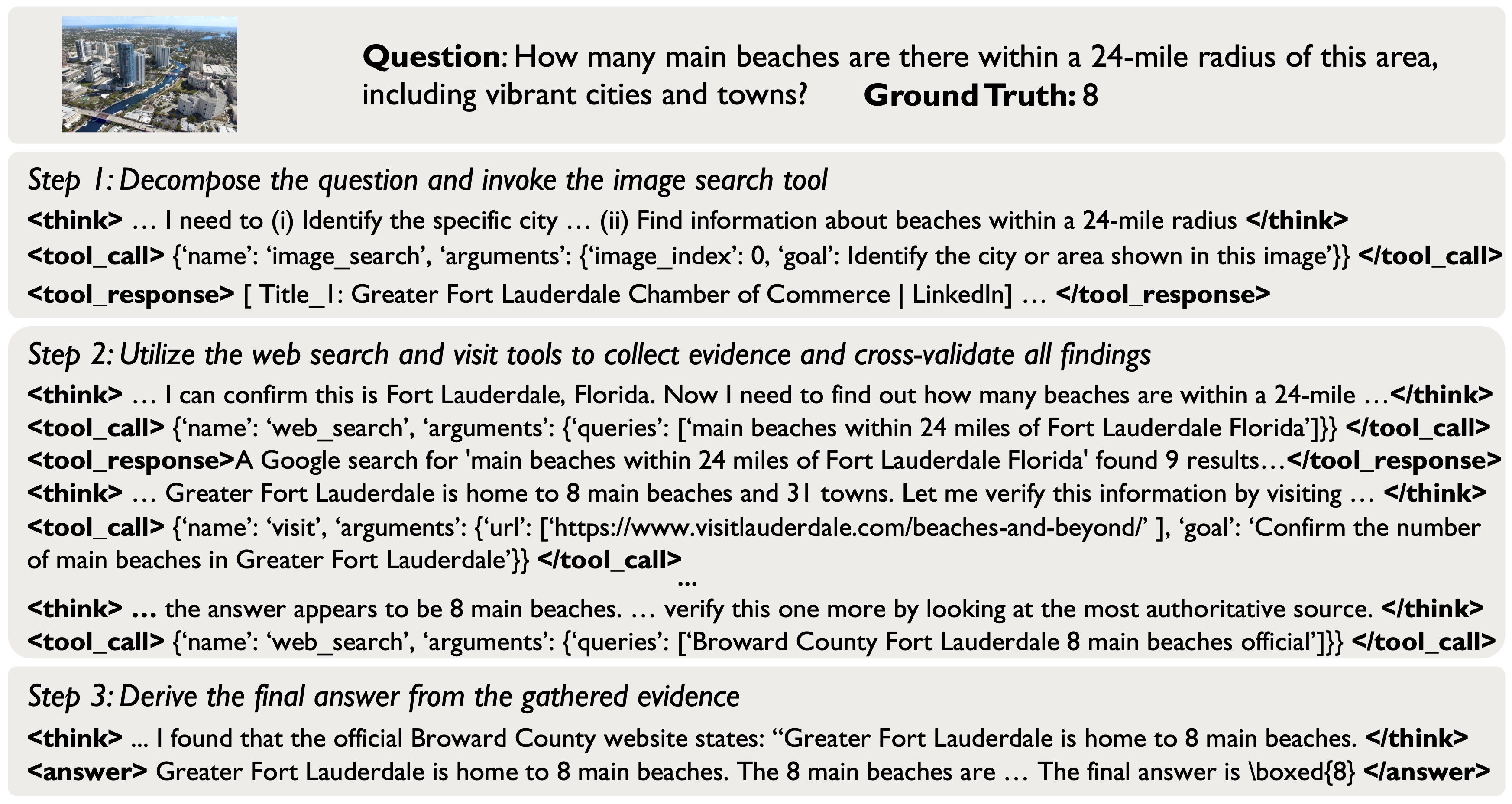
While Large Multimodal Models (LMMs) demonstrate impressive visual perception, they remain epistemically constrained by their static parametric knowledge. To transcend these boundaries, multimodal search models have been adopted to actively interact with the external environment for evidence retrieval. Diverging from prevailing paradigms that merely retrofit general LMMs with search tools as modular extensions, we explore the potential of building a multimodal agentic search model from scratch. Specifically, we make the following contributions: (i) we introduce Agentic Seeding, a dedicated phase designed to weave the foundational precursors necessary for eliciting agentic behaviors; (ii) we uncover a performance bottleneck in long-horizon interactions, where the increasing volume of interaction history overwhelms the model's ability to locate ground-truth evidence. To mitigate this, we propose V-Fold, an adaptive history-aware compression scheme that preserves recent dialogue turns in high fidelity while folding historical context into the visual space via rendering; and (iii) we develop POINTS-Seeker-8B, a state-of-the-art multimodal agentic search model that consistently outperforms existing models across six diverse benchmarks, effectively resolving the challenges of long-horizon, knowledge-intensive visual reasoning.
@article{liu2026pointsseeker,
title={POINTS-Seeker: Towards Training a Multimodal Agentic Search Model from Scratch},
author={Yikun Liu and Yuan Liu and Le Tian and Xiao Zhou and Jiangchao Yao and Yanfeng Wang and Weidi Xie},
journal={arXiv preprint arXiv:2604.14029},
year={2026}
}